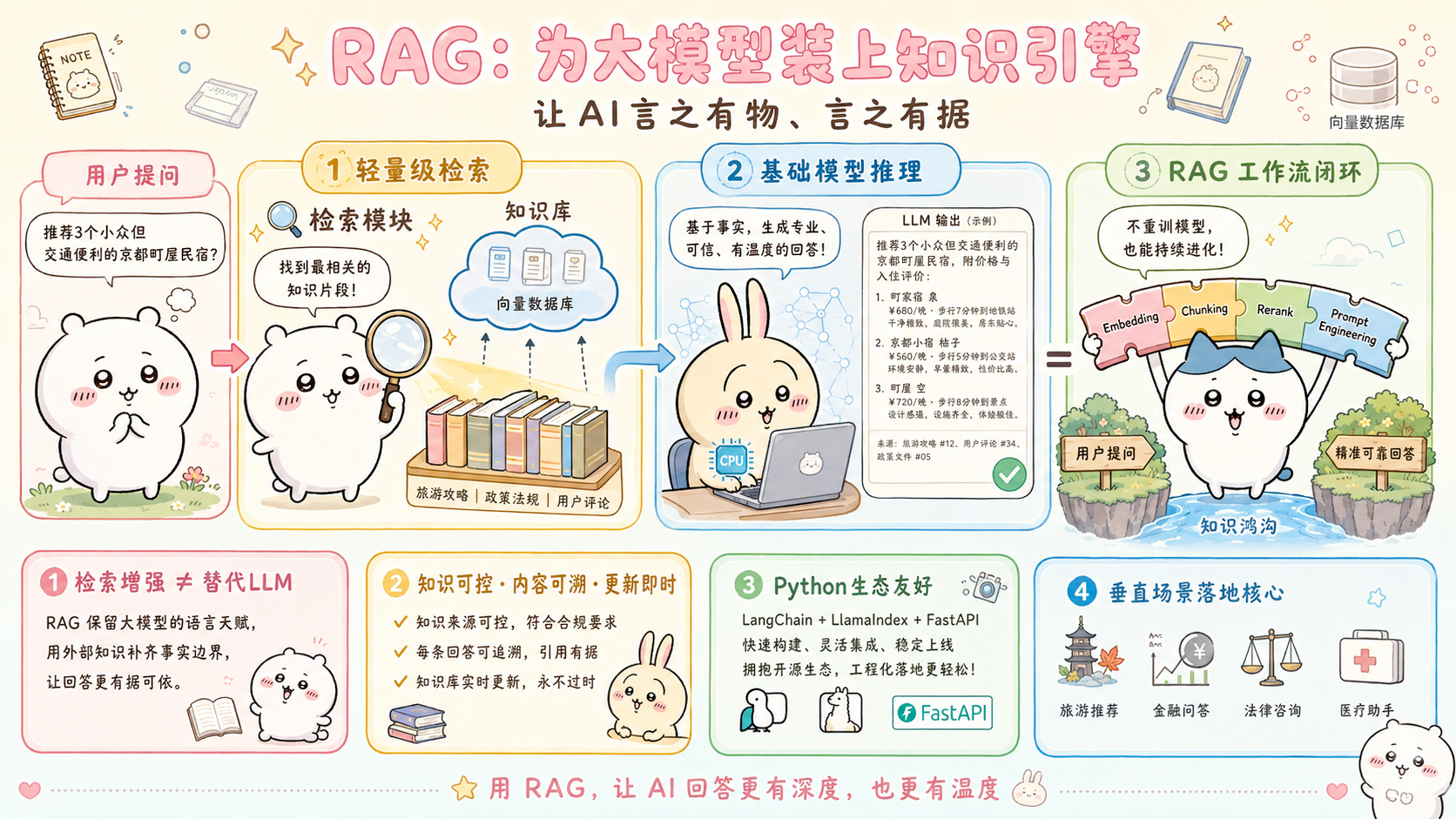
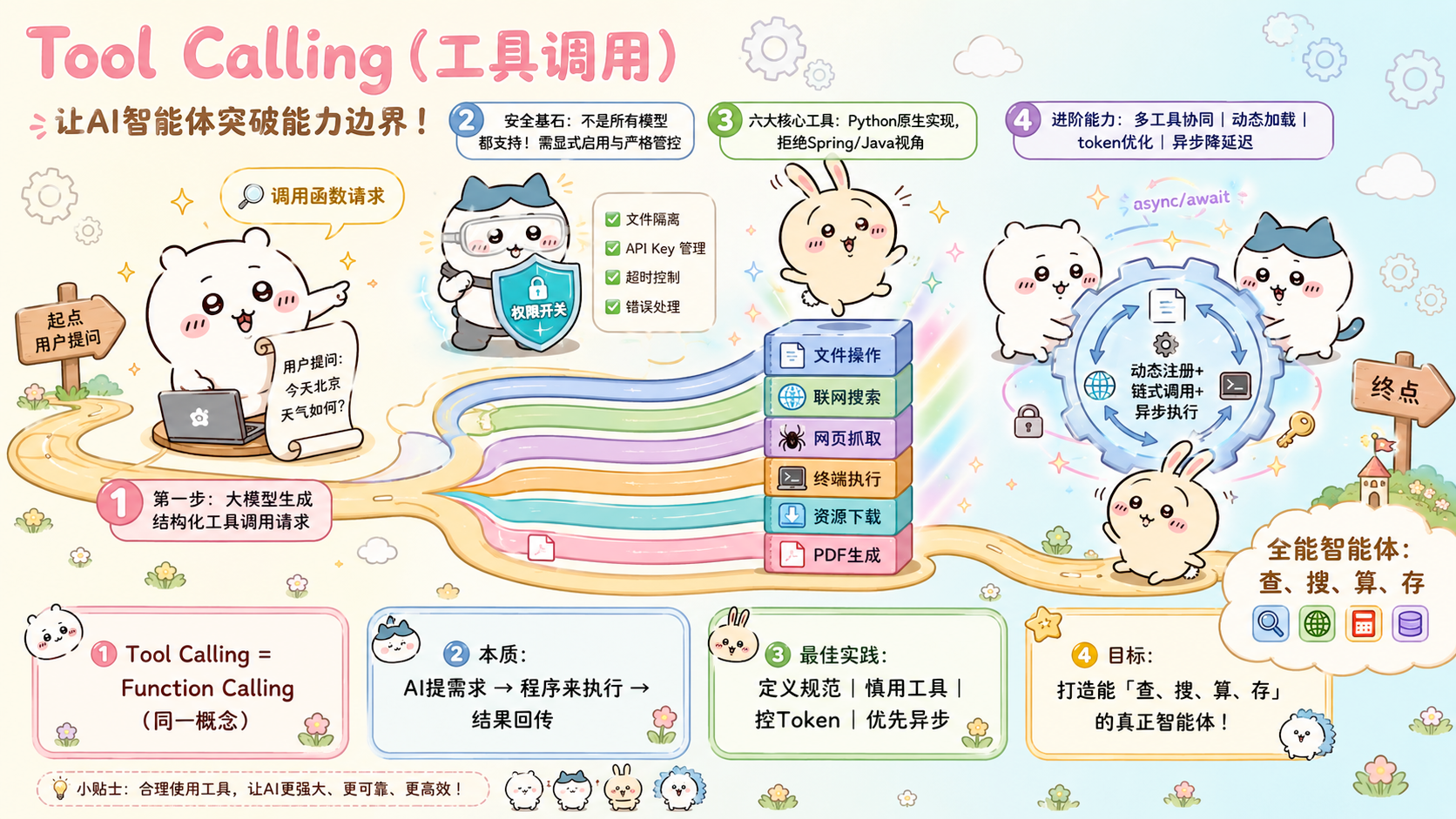
前言
在人工智能快速发展的今天,如何让 AI 模型高效、安全地访问外部数据和工具,已成为开发者面临的核心挑战。MCP(Model Context Protocol,模型上下文协议)应运而生,它提供了一套标准化的解决方案,让 AI 应用能够像使用 USB 接口一样方便地连接各种外部服务。本文将全面深入地介绍 MCP 的各个方面,帮助读者从零开始掌握这一重要技术。
第一部分:MCP 基础概念
1.1 什么是 MCP?
MCP(Model Context Protocol)是由 Anthropic 提出并开源的一种开放标准协议。它的核心目标是增强 AI 与外部系统的交互能力,为 AI 模型提供与外部工具、数据源和服务进行交互的标准化方式。
在没有 MCP 之前,开发者想让 AI 访问外部数据通常需要:
- 为每个数据源编写自定义的集成代码
- 处理各种不同的 API 格式和认证方式
- 反复解决相似的问题
MCP 的出现改变了这一局面。它将 AI 应用与外部系统的交互抽象为一套通用协议,就像 USB 标准化了设备连接一样。
MCP 的核心价值:
- 让 AI 能够访问实时数据,不再局限于训练数据的截止日期
- 使 AI 能够执行具体操作,而不仅仅是生成文本
- 提供标准化的方式与现有系统集成
- 降低 AI 应用开发的复杂度和重复劳动
1.2 为什么需要 MCP?
传统的 AI 应用开发面临几个痛点:
痛点一:数据孤岛
AI 模型通常被隔离在沙箱环境中,无法直接访问企业内部的数据库、文件系统或第三方 API。开发者需要编写大量的“胶水代码”来连接 AI 和外部系统。
痛点二:重复造轮子
不同的开发者、不同的项目都在做相似的集成工作。比如查询数据库的能力,A 项目做一遍,B 项目再做一遍,质量和标准参差不齐。
痛点三:缺乏统一标准
每个工具都有自己的 API 设计风格、认证方式、错误处理机制。AI 应用需要为每个工具编写特定的适配代码,维护成本极高。
痛点四:能力扩展困难
想给 AI 增加新能力(比如“发送邮件”),往往需要修改 AI 应用的代码,重新部署。缺乏动态发现和加载能力的机制。
MCP 通过标准化协议解决了以上所有问题。
1.3 MCP 的三大作用
作用一:轻松增强 AI 的能力
通过 MCP 协议,AI 应用可以轻松接入别人提供的服务,快速获得新能力。例如:
- 搜索网页:让 AI 能够检索最新信息
- 查询数据库:让 AI 能够访问结构化数据
- 调用第三方 API:让 AI 能够使用各种在线服务(天气、地图、支付等)
- 执行计算:让 AI 能够进行精确的数学计算
- 文件操作:让 AI 能够读写本地或云端的文件
作用二:统一标准,降低使用和理解成本
MCP 本质上是一个协议或标准,它本身不提供服务,而是定义了一套规范。就像 HTTP 协议统一了 Web 通信一样,MCP 统一了 AI 与工具的交互方式。这种标准化的好处包括:
- 开发者只需要学习一套协议,就可以使用任何兼容 MCP 的工具
- 工具开发者只需要实现 MCP 规范,就可以被任何 MCP 客户端调用
- 统一的请求/响应格式、错误码、能力协商机制
- 减少沟通成本和理解偏差
作用三:打造服务生态,造福广大开发者
标准化是形成生态的基础。类似于:
- 前端开发有 NPM 包管理器,可以复用海量的开源包
- 后端开发有 Maven/Gradle 仓库,可以方便地引入依赖
- 运维领域有 Docker Hub,可以分享容器镜像
- 移动开发有应用商店,可以分发 App
MCP 有望打造一个“AI 能力商店”。任何人都可以开发 MCP 服务并发布,其他开发者可以直接使用,无需重复开发。这将极大地丰富 AI 应用的能力边界,推动 AI 应用的普及和创新。
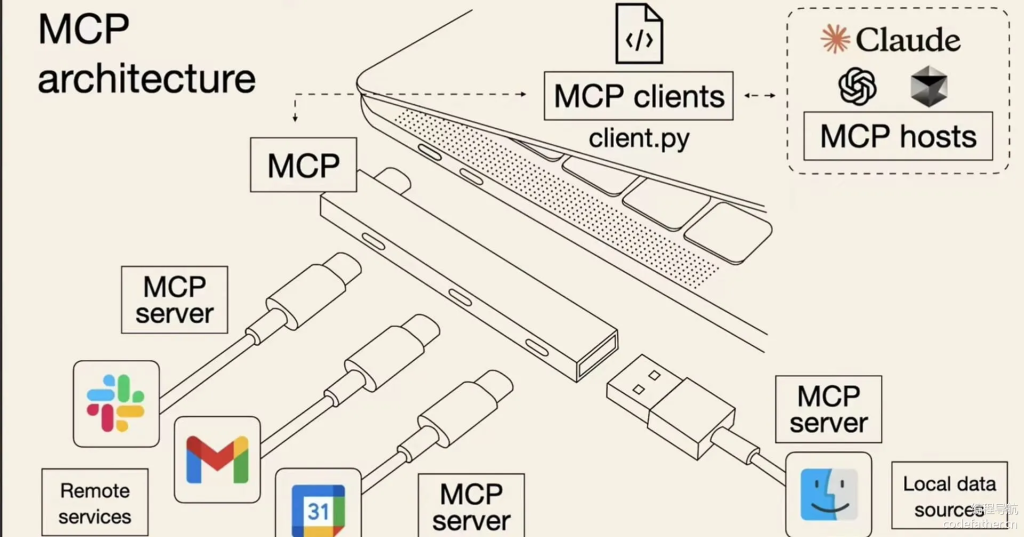
第二部分:MCP 架构深度解析
2.1 宏观架构
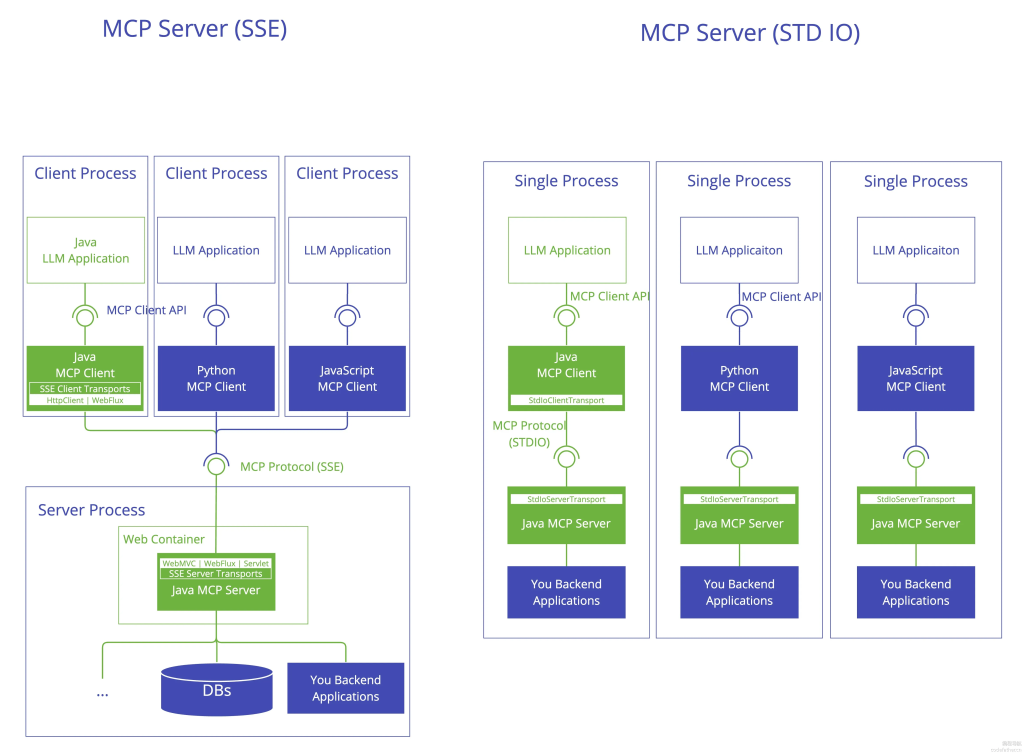
MCP 采用经典的“客户端-服务器”架构,其中:
MCP 客户端(Client):
- 运行在希望访问 MCP 服务的程序中
- 可以是 Claude Desktop、IDE 插件、AI 工具、Web 应用、后端服务等
- 负责发起请求、调用工具、接收结果
MCP 服务器(Server):
- 独立运行的程序,提供具体的功能
- 可以是一个本地进程,也可以是远程服务
- 一个服务器可以提供多个“工具”(Tools)、多个“资源”(Resources)
关键特性:
- 一个客户端可以同时连接到多个服务器
- 客户端和服务器之间通过标准化的协议通信
- 服务器可以动态地宣布自己提供的工具和资源
- 客户端可以在运行时发现服务器的新能力
这种架构带来了极大的灵活性:你可以把不同的能力拆分到不同的服务器中,按需启动和停止,互不影响。
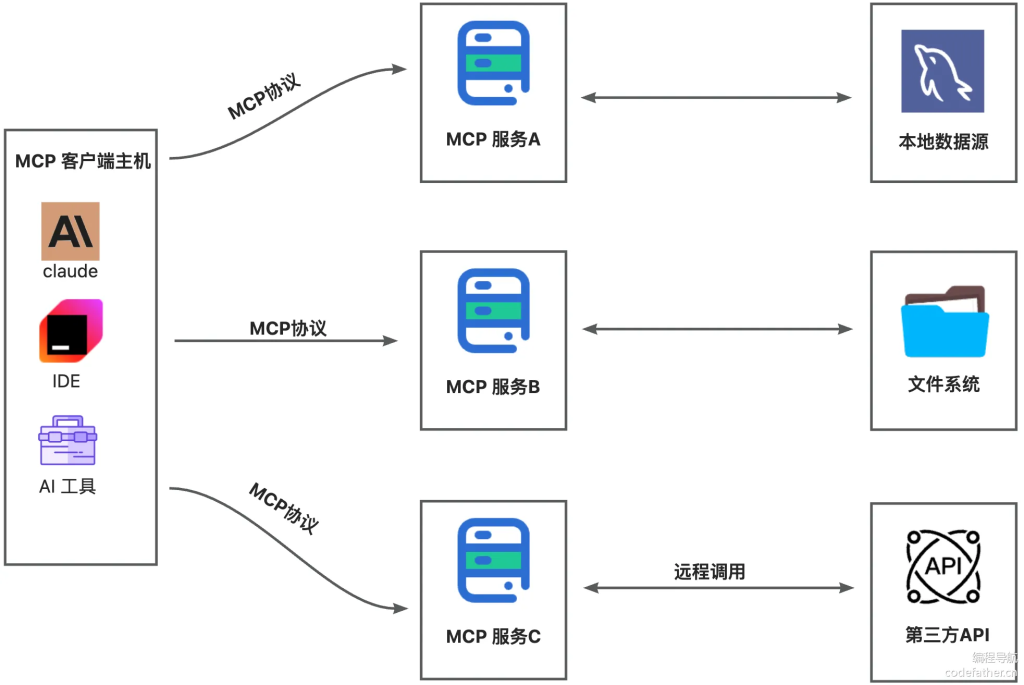
2.2 SDK 三层架构
MCP 官方为多种编程语言提供了 SDK(软件开发工具包),包括 Python、TypeScript/JavaScript、Java、Kotlin 等。这些 SDK 遵循统一的三层架构设计。
第一层:客户端/服务器层
这一层是开发者直接交互的接口:
- McpClient:负责客户端的初始化、连接管理、工具调用等操作
- McpServer:负责服务器的创建、工具注册、请求处理等
- 两者都使用下层的 Session 进行通信
第二层:会话层(Session)
会话层管理客户端和服务器之间的通信状态:
- 维护协议版本信息
- 管理请求-响应的匹配(Request-Response Correlation)
- 处理通知(Notifications)和请求(Requests)
- 实现会话生命周期管理(初始化、保活、关闭)
第三层:传输层(Transport)
传输层负责实际的字节传输,处理 JSON-RPC 消息的序列化和反序列化:
- Stdio 传输:通过标准输入输出流通信,适用于本地进程间通信,最简单、最常用
- SSE 传输:基于 Server-Sent Events,适用于远程通信,支持 HTTP 协议
- 其他传输方式可根据需要扩展(如 WebSocket)
这种分层设计的好处是:
- 各层职责清晰,易于理解和维护
- 可以独立替换传输层而不影响上层逻辑
- 便于实现跨语言、跨平台的互操作性
2.3 客户端详解
MCP 客户端是 AI 应用与 MCP 世界交互的入口。一个完善的 MCP 客户端需要实现以下功能:
核心功能:
- 协议版本协商
- 客户端启动时,会向服务器发送初始化请求
- 包含客户端支持的协议版本列表
- 服务器响应自己支持的版本,客户端选择兼容版本
- 如果版本不兼容,连接失败并给出提示
- 能力发现
- 客户端可以查询服务器提供了哪些工具
- 每个工具有名称、描述、参数 schema(JSON Schema 格式)
- 客户端可以根据这些信息动态生成 UI 或调用逻辑
- 工具调用
- 客户端发送工具调用请求,包含工具名称和参数
- 服务器执行工具并返回结果
- 支持同步和异步调用模式
- 资源管理
- 服务器可以提供静态资源(如文档、模板)
- 客户端可以读取这些资源
- 资源可以是文件、数据库记录、API 响应等任何形式
- 提示词交互
- 服务器可以提供提示词模板(Prompt Templates)
- 客户端获取模板并填充变量
- 用于生成结构化的提示词
额外特性:
- 根目录管理(Roots)
- 客户端可以告知服务器可访问的文件系统根路径
- 服务器在授权范围内读写文件
- 增强安全性
- 采样控制(Sampling)
- 客户端可以请求服务器生成文本(用于 AI 辅助功能)
- 服务器可以控制采样参数(temperature、top_p 等)
- 适用于需要 AI 推理的工具
- 同步/异步操作
- 支持请求-响应模式(同步)
- 支持通知模式(异步,无需响应)
- 支持进度通知(长时间操作)
传输方式详解:
Stdio 传输的特点:
- 客户端启动服务器子进程
- 通过子进程的标准输入输出通信
- 非常适合本地工具、脚本、命令行程序
- 无需网络配置,安全性高
- 启动速度快,资源占用少
SSE 传输的特点:
- 基于 HTTP,支持远程调用
- 服务器可以主动推送消息(Server-Sent Events)
- 适合分布式部署、微服务架构
- 可以跨越网络边界,实现客户端和服务器的物理分离
- 便于扩展和维护
2.4 服务端详解
MCP 服务器是能力的提供者。一个典型的 MCP 服务器需要实现以下功能:
核心职责:
- 协议实现
- 实现 MCP 协议规定的标准消息类型
- 正确处理客户端的初始化、工具列表查询、工具调用等请求
- 返回符合规范的错误信息
- 工具管理
- 注册一个或多个工具
- 每个工具有唯一的名称、人类可读的描述
- 定义参数 schema(JSON Schema),便于客户端验证和生成 UI
- 实现工具的具体逻辑
- 资源管理
- 提供静态或动态资源
- 资源可以带 URI,支持按路径读取
- 支持资源模板(URI Template)
- 提示词管理
- 提供提示词模板
- 支持变量替换
- 可以返回渲染后的完整提示词
- 日志与通知
- 支持向客户端发送日志消息(不同级别:debug、info、warning、error)
- 支持进度通知(长时间操作反馈)
- 支持自定义通知
- 并发处理
- 支持多客户端同时连接(对于远程服务)
- 处理好请求的并发控制和资源隔离
传输方式:
与客户端对称,服务端也支持:
- Stdio 传输:作为子进程被客户端启动,通过标准输入输出通信
- SSE 传输:作为 HTTP 服务运行,监听端口,接受远程连接
设计优势:
这种设计的最大优势是解耦:
- 客户端和服务器可以使用不同的编程语言开发
- 服务器可以独立部署、升级、扩展
- 客户端无需知道服务器的内部实现细节
- 可以轻松替换或组合不同的服务器
例如,你可以用 Python 开发一个天气查询 MCP 服务,用 Node.js 开发一个数据库查询服务,然后同一个 AI 应用(比如 Python 写的)可以同时调用这两个服务。调用方不需要关心服务端是什么语言实现的。
2.5 连接建立流程详解
客户端和服务器建立连接的完整流程如下:
- 传输层握手
- 对于 Stdio:客户端启动服务器子进程
- 对于 SSE:客户端建立 HTTP 连接,服务器响应 endpoint
- 初始化请求
- 客户端发送
initialize请求 - 包含客户端名称、版本、支持的协议版本
- 包含客户端能力声明(支持哪些可选特性)
- 客户端发送
- 初始化响应
- 服务器响应
initialize结果 - 包含服务器名称、版本、选择的协议版本
- 包含服务器能力声明
- 服务器响应
- 初始化完成通知
- 客户端发送
initialized通知 - 表示初始化阶段结束,可以开始正常通信
- 客户端发送
- 能力协商
- 客户端可发送
tools/list获取工具列表 - 客户端可发送
resources/list获取资源列表 - 客户端可发送
prompts/list获取提示词列表
- 客户端可发送
- 正常消息交互
- 客户端发送
tools/call请求执行工具 - 服务器执行并返回结果
- 可选的进度通知、日志消息
- 客户端发送
- 会话结束
- 客户端或服务器可以关闭连接
- 对于 Stdio,关闭子进程
- 对于 SSE,关闭 HTTP 连接
第三部分:MCP 核心概念详解
3.1 工具(Tools)
工具是 MCP 中最核心的概念。一个工具代表一个可被 AI 调用的函数或操作。
工具的定义包含:
name:工具的唯一标识符,使用小写字母和下划线,如get_weatherdescription:人类可读的描述,说明工具的功能和适用场景inputSchema:输入参数的 JSON Schema,定义了参数的类型、是否必需、默认值等
工具的典型例子:
- 天气查询:输入城市名称,返回天气信息
- 数据库查询:输入 SQL 语句,返回查询结果
- 发送邮件:输入收件人、主题、正文,发送邮件
- 文件读写:输入文件路径和内容,读写文件
- 计算器:输入表达式,返回计算结果
工具调用的流程:
- 客户端发送
tools/call请求,传入工具名和参数 - 服务器根据工具名找到对应的处理函数
- 服务器验证参数是否符合 schema
- 服务器执行工具逻辑
- 服务器返回结果(成功或错误)
- 客户端接收结果并继续处理
3.2 资源(Resources)
资源是服务器提供的静态或动态数据。与工具不同,资源主要是“读”操作,类似于文件系统的概念。
资源的特点:
- 每个资源有唯一的 URI
- 支持按路径读取
- 可以是静态内容(如配置文件、文档模板)
- 也可以是动态生成的内容(如数据库查询结果、API 响应)
- 支持资源模板(URI Template),可以匹配多个类似路径
资源的应用场景:
- 提供 API 文档,供 AI 阅读
- 提供项目配置文件
- 提供数据库表结构描述
- 提供日志文件内容
- 提供当前时间、系统状态等动态信息
资源的访问流程:
- 客户端发送
resources/read请求,传入 URI - 服务器解析 URI,获取对应的内容
- 服务器返回内容(文本或二进制,带 MIME 类型)
- 客户端使用内容
3.3 提示词(Prompts)
提示词是服务器提供的预定义提示模板。这对于标准化 AI 交互非常有用。
提示词的特点:
- 有名称和描述
- 可以定义变量占位符
- 服务器可以渲染模板,也可以返回模板让客户端渲染
- 可以包含多段消息(system、user、assistant 交替)
提示词的应用场景:
- 提供特定领域的专家角色定义
- 提供常见的查询模板
- 提供格式化的输出模板
- 提供多轮对话的初始结构
提示词的使用流程:
- 客户端发送
prompts/list获取可用提示词 - 客户端发送
prompts/get请求,传入提示词名称和变量值 - 服务器返回渲染后的消息列表
- 客户端将消息发送给 LLM
3.4 采样(Sampling)
采样是一个高级特性,允许服务器请求客户端生成文本。这对于那些需要 AI 辅助决策的工具特别有用。
采样的工作流程:
- 服务器在处理工具调用时,需要 AI 生成一些文本
- 服务器发送
sampling/createMessage请求给客户端 - 客户端(通常集成了 LLM)生成文本
- 客户端返回生成结果给服务器
- 服务器继续执行
采样的控制参数:
messages:对话历史model:指定使用的模型(可选)max_tokens:最大生成 token 数temperature:随机性控制top_p:核采样参数stop_sequences:停止序列
3.5 通知(Notifications)
通知是一种不需要响应的消息,用于单向通信。
通知的类型:
notifications/initialized:初始化完成通知notifications/cancelled:请求取消通知notifications/progress:进度通知notifications/logMessage:日志消息通知
通知的应用:
- 长时间操作中向客户端报告进度
- 服务器向客户端发送日志信息用于调试
- 客户端取消一个正在执行的请求
第四部分:MCP 的应用场景与实战
4.1 场景一:让 AI 获取实时信息
需求分析:AI 大模型的训练数据存在截止日期,无法获取最新的信息。通过 MCP,可以让 AI 实时查询外部数据源。
实现思路:
- 开发一个信息查询 MCP 服务器
- 提供诸如
get_weather、get_news、get_stock_price等工具 - 每个工具内部调用相应的第三方 API
- AI 应用(MCP 客户端)调用这些工具获取实时数据
典型工具示例:
get_current_weather:输入城市,调用天气 API,返回温度、湿度、天气状况search_web:输入查询词,调用搜索 API,返回搜索结果get_exchange_rate:输入货币对,获取实时汇率get_time:获取当前时间(解决 AI 不知道“现在”的问题)
4.2 场景二:AI 操作本地文件
需求分析:让 AI 能够读取、写入、管理用户本地的文件和目录。
实现思路:
- 开发文件操作 MCP 服务器
- 提供文件读写、列表、搜索等工具
- 客户端告知服务器可访问的根目录(Roots 特性)
- 服务器在授权范围内操作
典型工具示例:
list_directory:列出目录内容read_file:读取文件内容write_file:写入文件search_files:按名称或内容搜索文件get_file_info:获取文件元数据(大小、修改时间等)
安全考虑:
- 通过 Roots 限制访问范围
- 对敏感操作需要用户确认
- 记录操作日志
4.3 场景三:AI 与数据库交互
需求分析:让 AI 能够查询和分析数据库中的数据,用于数据报告、智能问答等。
实现思路:
- 开发数据库 MCP 服务器
- 提供
query_database工具,接收 SQL 语句 - 提供
list_tables、describe_table等辅助工具 - 注意 SQL 注入防护和查询结果大小限制
典型工具示例:
execute_query:执行只读 SQL 查询,返回结果集list_tables:列出所有表名get_table_schema:获取表的结构信息get_database_info:获取数据库版本、大小等元信息
高级用法:
- AI 可以先调用
list_tables了解数据库结构 - 然后生成 SQL 查询
- 执行查询并分析结果
- 用于 BI 分析、智能客服等场景
4.4 场景四:AI 调用第三方 API
需求分析:许多在线服务提供 API,让 AI 能够使用这些服务(如发送邮件、创建日历事件、发推文等)。
实现思路:
- 开发 API 调用的 MCP 服务器
- 将第三方 API 封装为 MCP 工具
- 处理认证(API Key、OAuth 等)
- 处理错误和重试
典型工具示例:
send_email:通过 SMTP 或邮件服务 API 发送邮件create_calendar_event:在 Google Calendar 创建事件post_tweet:发布推文upload_file:上传文件到云存储send_slack_message:发送 Slack 消息
4.5 场景五:构建复合 AI 应用(链式调用)
需求分析:单个工具的能力有限,通过组合多个工具可以实现复杂的任务。
实现思路:
- AI 应用先调用一个工具获取初步信息
- 根据返回结果,决定下一步调用哪个工具
- 可以循环调用,实现多步推理
典型流程示例(智能旅行助手):
- 用户问:“北京今天天气怎么样?适合去哪个公园?”
- AI 调用
get_weather,输入“北京” - 返回:晴天,25度
- AI 调用
search_parks,输入“北京 公园” - 返回公园列表
- AI 根据天气和公园信息,推荐一个公园
4.6 场景六:MCP 服务编排(多个服务器协同)
需求分析:一个 AI 应用可能需要同时使用多个 MCP 服务器的能力。
实现思路:
- 客户端连接到多个 MCP 服务器(如天气服务器、文件服务器、数据库服务器)
- 客户端汇总所有服务器的工具列表
- AI 可以透明地调用任何一个服务器的工具
- 工具调用请求根据工具名称路由到对应的服务器
优势:
- 能力模块化,每个服务器专注于一个领域
- 便于团队协作开发
- 可以独立部署和扩展
- 故障隔离(一个服务器挂了不影响其他)
第五部分:MCP 开发指南(Python )
5.1 环境准备
安装 MCP Python SDK
pip install mcpbash
或者从源码安装:
bash
git clone https://github.com/modelcontextprotocol/python-sdk.git
cd python-sdk
pip install -e .验证安装
python
import mcp
print(mcp.__version__)5.2 开发一个简单的 MCP 服务器
以下是一个完整的 Python MCP 服务器示例,提供两个简单的工具:加法和获取当前时间。
python
import asyncio
from datetime import datetime
from mcp.server import Server, NotificationOptions
from mcp.server.models import InitializationOptions
import mcp.server.stdio
import mcp.types as types
# 创建服务器实例
server = Server("example-server")
# 定义工具列表
@server.list_tools()
async def handle_list_tools() -> list[types.Tool]:
return [
types.Tool(
name="add",
description="两个数相加",
inputSchema={
"type": "object",
"properties": {
"a": {"type": "number", "description": "第一个数"},
"b": {"type": "number", "description": "第二个数"},
},
"required": ["a", "b"],
},
),
types.Tool(
name="get_current_time",
description="获取当前时间",
inputSchema={
"type": "object",
"properties": {
"format": {
"type": "string",
"description": "时间格式,默认为 '%Y-%m-%d %H:%M:%S'",
"enum": ["full", "date", "time"]
}
},
},
),
]
# 实现工具调用逻辑
@server.call_tool()
async def handle_call_tool(
name: str, arguments: dict | None
) -> list[types.TextContent | types.ImageContent | types.EmbeddedResource]:
if name == "add":
a = arguments.get("a")
b = arguments.get("b")
if a is None or b is None:
raise ValueError("Missing arguments a or b")
result = a + b
return [types.TextContent(type="text", text=str(result))]
elif name == "get_current_time":
fmt = arguments.get("format", "full")
now = datetime.now()
if fmt == "full":
time_str = now.strftime("%Y-%m-%d %H:%M:%S")
elif fmt == "date":
time_str = now.strftime("%Y-%m-%d")
elif fmt == "time":
time_str = now.strftime("%H:%M:%S")
else:
time_str = str(now)
return [types.TextContent(type="text", text=time_str)]
else:
raise ValueError(f"Unknown tool: {name}")
# 启动服务器
async def main():
async with mcp.server.stdio.stdio_server() as (read_stream, write_stream):
await server.run(
read_stream,
write_stream,
InitializationOptions(
server_name="example-server",
server_version="0.1.0",
),
)
if __name__ == "__main__":
asyncio.run(main())5.3 开发一个带有资源的 MCP 服务器
除了工具,服务器还可以提供资源。以下示例提供了一个配置文件资源:
python
import asyncio
import json
from mcp.server import Server
import mcp.server.stdio
import mcp.types as types
server = Server("config-server")
# 定义资源列表
@server.list_resources()
async def handle_list_resources() -> list[types.Resource]:
return [
types.Resource(
uri="config://app/settings",
name="应用配置",
description="JSON 格式的应用配置",
mimeType="application/json",
),
]
# 读取资源
@server.read_resource()
async def handle_read_resource(uri: str) -> str | bytes:
if uri == "config://app/settings":
config = {
"app_name": "My MCP App",
"version": "1.0.0",
"debug": True,
"max_results": 100,
}
return json.dumps(config, indent=2)
else:
raise ValueError(f"Unknown resource: {uri}")
async def main():
async with mcp.server.stdio.stdio_server() as (read_stream, write_stream):
await server.run(read_stream, write_stream, ...)
if __name__ == "__main__":
asyncio.run(main())5.4 开发一个 MCP 客户端
以下是一个简单的 MCP 客户端示例,连接到服务器并调用工具:
python
import asyncio
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
async def main():
# 创建服务器参数(启动子进程)
server_params = StdioServerParameters(
command="python",
args=["your_server.py"], # 替换为你的服务器脚本
)
# 建立连接
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# 初始化会话
await session.initialize()
# 列出工具
tools = await session.list_tools()
print("可用工具:")
for tool in tools:
print(f" - {tool.name}: {tool.description}")
# 调用工具
result = await session.call_tool("add", arguments={"a": 5, "b": 3})
print(f"5 + 3 = {result.content[0].text}")
# 调用另一个工具
time_result = await session.call_tool("get_current_time", arguments={"format": "full"})
print(f"当前时间:{time_result.content[0].text}")
if __name__ == "__main__":
asyncio.run(main())5.5 错误处理最佳实践
在 MCP 开发中,正确的错误处理非常重要:
python
@server.call_tool()
async def handle_call_tool(name: str, arguments: dict | None):
try:
if name == "risky_operation":
# 参数验证
if not arguments or "path" not in arguments:
raise ValueError("Missing required argument: path")
# 执行操作
result = do_something_risky(arguments["path"])
return [types.TextContent(type="text", text=str(result))]
except FileNotFoundError as e:
# 返回明确的错误信息
raise Exception(f"文件未找到:{e}")
except PermissionError as e:
raise Exception(f"权限不足:{e}")
except Exception as e:
# 记录日志,然后抛出
print(f"Unexpected error: {e}")
raise Exception(f"操作失败:{e}")5.6 使用 SSE 传输(远程服务器)
如果需要将 MCP 服务器作为远程服务运行,可以使用 SSE 传输。
SSE 服务器端:
python
from mcp.server.sse import SseServerTransport
from starlette.applications import Starlette
from starlette.routing import Route
import uvicorn
# 创建 SSE 传输
sse = SseServerTransport("/messages")
# 定义处理函数
async def handle_sse(request):
async with sse.connect_sse(
request.scope, request.receive, request.send
) as streams:
await server.run(
streams[0], streams[1], server.get_initialization_options()
)
# 创建 Starlette 应用
app = Starlette(
routes=[
Route("/sse", endpoint=handle_sse),
Route("/messages", endpoint=sse.handle_post_message, methods=["POST"]),
]
)
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)SSE 客户端:
python
from mcp import ClientSession
from mcp.client.sse import sse_client
async def main():
async with sse_client("http://localhost:8000/sse") as (read, write):
async with ClientSession(read, write) as session:
await session.initialize()
tools = await session.list_tools()
print(tools)5.7 异步与并发处理
MCP Python SDK 基于 asyncio,天然支持异步和并发。在处理长时间操作时,可以发送进度通知:
python
@server.call_tool()
async def handle_call_tool(name: str, arguments: dict | None):
if name == "long_task":
total = arguments.get("total", 100)
for i in range(total):
# 发送进度通知
await server.send_progress_notification(
progress=i + 1,
total=total,
message=f"处理中 {i+1}/{total}"
)
await asyncio.sleep(0.1) # 模拟工作
return [types.TextContent(type="text", text="任务完成")]第六部分:MCP 部署方案
6.1 本地进程部署
这是最简单的部署方式,适合开发测试和个人使用。
架构:
- 客户端(AI 应用)作为主进程
- MCP 服务器作为子进程启动
- 通过 Stdio 传输通信
优点:
- 无需网络配置,开箱即用
- 延迟极低(进程内通信)
- 安全性高(不暴露网络端口)
- 资源占用少
缺点:
- 每个客户端启动独立的服务器进程
- 无法跨机器共享服务
- 扩展性有限
适用场景:
- 本地开发调试
- 个人 AI 助手
- 脚本和自动化任务
6.2 远程服务部署
将 MCP 服务器部署为独立的网络服务,多个客户端可以共享。
架构:
- MCP 服务器作为 HTTP 服务运行(SSE 传输)
- 监听端口,接受远程连接
- 可部署在云服务器、容器中
优点:
- 服务复用,节省资源
- 集中管理,便于升级
- 可以水平扩展
缺点:
- 需要网络配置和认证
- 网络延迟
- 需要处理并发和负载
适用场景:
- 企业级应用
- 团队协作
- 生产环境
6.3 容器化部署(Docker)
使用 Docker 容器化 MCP 服务,便于分发和部署。
Dockerfile 示例:
dockerfile
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
# 暴露 SSE 端口(如果使用 SSE)
EXPOSE 8000
# 启动命令
CMD ["python", "server.py"]docker-compose.yml 示例:
yaml
version: '3.8'
services:
mcp-weather:
build: ./weather-server
ports:
- "8001:8000"
environment:
- WEATHER_API_KEY=${WEATHER_API_KEY}
mcp-database:
build: ./db-server
ports:
- "8002:8000"
environment:
- DB_CONNECTION_STRING=${DB_CONNECTION_STRING}
mcp-file:
build: ./file-server
ports:
- "8003:8000"
volumes:
- ./data:/data6.4 服务网格与发现
当 MCP 服务数量增多时,需要服务发现机制。
简单方案:
- 使用 Nginx 或类似的反向代理
- 通过路径区分不同的服务
- 例如:
/weather/*路由到天气服务,/db/*路由到数据库服务
高级方案:
- 使用 Consul、etcd 等服务注册中心
- MCP 客户端通过服务名动态发现服务器地址
- 支持负载均衡和故障转移
服务发现示例(伪代码):
python
async def discover_mcp_server(service_name: str):
# 从 Consul 获取服务地址
response = await http_client.get(f"http://consul:8500/v1/health/service/{service_name}")
services = response.json()
if services:
address = services[0]["Service"]["Address"]
port = services[0]["Service"]["Port"]
return f"http://{address}:{port}/sse"
raise Exception(f"Service {service_name} not found")
async def main():
weather_url = await discover_mcp_server("mcp-weather")
async with sse_client(weather_url) as (read, write):
# 使用天气服务
pass6.5 安全加固
生产环境部署需要考虑安全:
- 网络隔离:将 MCP 服务部署在内网,仅允许信任的客户端访问
- 认证:实现 API Key 或 JWT 认证
- TLS:使用 HTTPS 加密通信
- 速率限制:防止滥用
- 审计日志:记录所有工具调用
第七部分:MCP 安全指南
7.1 认证与授权
API Key 认证:
python
from fastapi import FastAPI, Header, HTTPException
app = FastAPI()
VALID_KEYS = {"sk-123456", "sk-789012"}
@app.post("/messages")
async def handle_message(x_api_key: str = Header(...)):
if x_api_key not in VALID_KEYS:
raise HTTPException(status_code=401, detail="Invalid API Key")
# 处理请求OAuth 2.0:对于需要访问用户数据的场景(如 Google Calendar、GitHub),应使用 OAuth 流程。
授权粒度:
- 哪些客户端可以调用哪些工具?
- 对于敏感工具(如删除文件),是否需要额外确认?
7.2 输入验证与安全
参数验证:
- 始终验证客户端传入的参数,不能信任任何输入
- 对于 SQL 查询工具,使用参数化查询或只读账户
- 对于文件操作工具,路径规范化,防止路径遍历攻击
路径遍历防护示例:
python
import os
def safe_path(base_dir: str, user_path: str) -> str:
# 规范化路径
abs_base = os.path.abspath(base_dir)
abs_path = os.path.abspath(os.path.join(base_dir, user_path))
# 检查是否在基准目录内
if not abs_path.startswith(abs_base):
raise ValueError("Access denied")
return abs_path命令注入防护:
- 避免直接拼接系统命令
- 使用参数化接口或
subprocess.run的列表形式
7.3 数据安全
传输加密:
- 对于远程 MCP 服务,必须使用 TLS
- 不要在生产环境使用明文 HTTP
敏感信息处理:
- 不要在日志中记录 API Key、密码等敏感信息
- 工具返回的结果中,如包含敏感数据,考虑脱敏
数据最小化:
- 只返回必要的数据
- 对于数据库查询,限制结果集大小
7.4 审计与监控
日志记录:
- 记录每个工具调用的时间、客户端、工具名、参数(脱敏后)
- 记录错误和异常
- 定期审查日志
监控指标:
- 请求次数
- 响应时间
- 错误率
- 资源使用(CPU、内存)
7.5 安全最佳实践清单
- 使用非特权用户运行 MCP 服务
- 启用认证(API Key 或 OAuth)
- 使用 TLS 加密通信
- 实施速率限制
- 验证和清理所有输入
- 使用最小权限原则(文件系统、数据库)
- 记录审计日志
- 定期更新依赖库
- 进行安全测试
第八部分:MCP 常见问题与故障排查
8.1 连接问题
问题:客户端无法连接到服务器
排查步骤:
- 检查服务器是否运行:
ps aux | grep mcp - 检查端口是否监听(SSE):
netstat -an | grep 8000 - 检查防火墙规则
- 查看服务器日志是否有错误
Stdio 特定问题:
- 确保服务器脚本有执行权限
- 检查 Python 环境路径是否正确
- 测试手动运行服务器脚本是否正常
8.2 工具调用失败
问题:工具返回错误或超时
排查步骤:
- 检查传入的参数类型和值是否符合 schema
- 检查工具内部是否有异常(查看日志)
- 对于网络请求类工具,检查网络连通性
- 检查 API 密钥是否有效
调试技巧:
- 在工具函数中添加详细的日志
- 使用 try-except 捕获异常并返回友好错误信息
- 对于复杂操作,添加超时机制
8.3 性能问题
问题:工具响应慢
优化建议:
- 使用缓存减少重复计算
- 对于数据库查询,添加索引
- 考虑异步处理长时间任务
- 增加服务器资源
8.4 版本兼容性
问题:协议版本不兼容
解决方案:
- 升级 MCP SDK 到最新版本
- 或降级到兼容版本
- 检查服务器和客户端使用的 SDK 版本
第九部分:MCP 与其他技术的对比
9.1 MCP vs Function Calling
| 维度 | MCP | Function Calling(OpenAI 等) |
|---|---|---|
| 标准 | 开放协议,多厂商支持 | 各厂商自定义 |
| 服务发现 | 动态(list_tools) | 静态(预先定义) |
| 传输 | Stdio、SSE、可扩展 | 通常 HTTP |
| 资源管理 | 内置资源(Resources) | 无 |
| 提示词管理 | 内置提示词模板 | 无 |
| 并发 | 支持多客户端 | 单次调用 |
| 部署 | 可独立部署 | 集成在应用中 |
选择建议:
- 如果你需要构建可复用的、独立部署的工具服务,MCP 更合适
- 如果只是简单的几个函数调用,Function Calling 更轻量
9.2 MCP vs 传统 API
| 维度 | MCP | REST API |
|---|---|---|
| 设计目标 | AI 友好 | 通用 |
| 自描述 | 工具列表、参数 schema | OpenAPI/Swagger |
| 交互模式 | 请求-响应 + 通知 | 主要是请求-响应 |
| 传输 | Stdio、SSE、HTTP | HTTP |
| 客户端 | AI 应用 | 任何 HTTP 客户端 |
MCP 可以看作是专门为 AI 应用优化的 API 协议。
9.3 MCP vs Plugin 生态
类似 ChatGPT Plugin,但 MCP 是开放标准,不绑定任何特定 AI 提供商。这意味着:
- 你的 MCP 服务可以被任何支持 MCP 的 AI 应用使用
- 不会被锁定在单一平台
- 可以自托管,保护数据隐私
第十部分:MCP 生态与未来展望
10.1 现有生态
目前 MCP 生态正在快速发展:
官方 SDK:
- Python SDK
- TypeScript/JavaScript SDK
- Java/Kotlin SDK
- C# SDK(社区)
已知的 MCP 服务器:
- 文件系统服务器(读写本地文件)
- 数据库服务器(PostgreSQL、SQLite 等)
- GitHub 服务器(仓库操作)
- Slack 服务器(消息发送)
- 天气服务器
- 搜索引擎服务器
支持 MCP 的客户端:
- Claude Desktop
- Continue(VSCode 扩展)
- 各种 AI 应用框架
10.2 未来发展方向
更丰富的传输层:
- WebSocket 支持
- gRPC 支持
- 消息队列集成
增强的安全性:
- 细粒度的权限模型
- 沙箱执行环境
- 零信任架构
工具链完善:
- MCP 服务注册中心
- MCP 服务市场
- 可视化开发工具
- 调试器和性能分析工具
标准化扩展:
- 工作流编排(多个工具的组合)
- 事件订阅
- 流式响应
10.3 如何参与
- 阅读官方文档:https://modelcontextprotocol.io
- 贡献代码到 GitHub
- 开发自己的 MCP 服务器并分享
- 在社区中提出建议和反馈
第十一部分:总结
MCP 是 AI 应用开发领域的一项重要创新。它通过标准化协议,解决了 AI 与外部系统交互的碎片化问题,为构建强大、可扩展的 AI 应用提供了坚实的基础。
核心要点回顾:
- MCP 是什么:一个开放协议,标准化 AI 与外部工具的交互方式
- 架构:客户端-服务器模式,支持 Stdio 和 SSE 传输
- 核心概念:工具、资源、提示词、采样、通知
- 应用场景:实时信息、文件操作、数据库、第三方 API、复合应用
- 开发:提供 Python SDK,开发简单
- 部署:本地进程、远程服务、容器化
- 安全:认证、授权、输入验证、审计
- 生态:正在快速发展,前景广阔
对于开发者来说,现在正是学习和掌握 MCP 的好时机。无论你是 AI 应用开发者,还是工具服务提供者,MCP 都能帮助你更高效地构建产品。
附录:参考资料
本文档为 MCP 完整学习指南,持续更新中。如有错误或建议,欢迎指正。